Performance Tuning¶
Sailfish uses default settings that should make most simulations run at a reasonable speed on modern GPUs. There are however several tunable parameters that can be used to increase the performance of specific simulations. Finding the optimal values of these parameters requires some experimentation on a case-by-case basis. The guide below suggests some useful strategies. In all following subsections we will assume that the CUDA backend is used.
General tuning strategies¶
Adjusting the block size¶
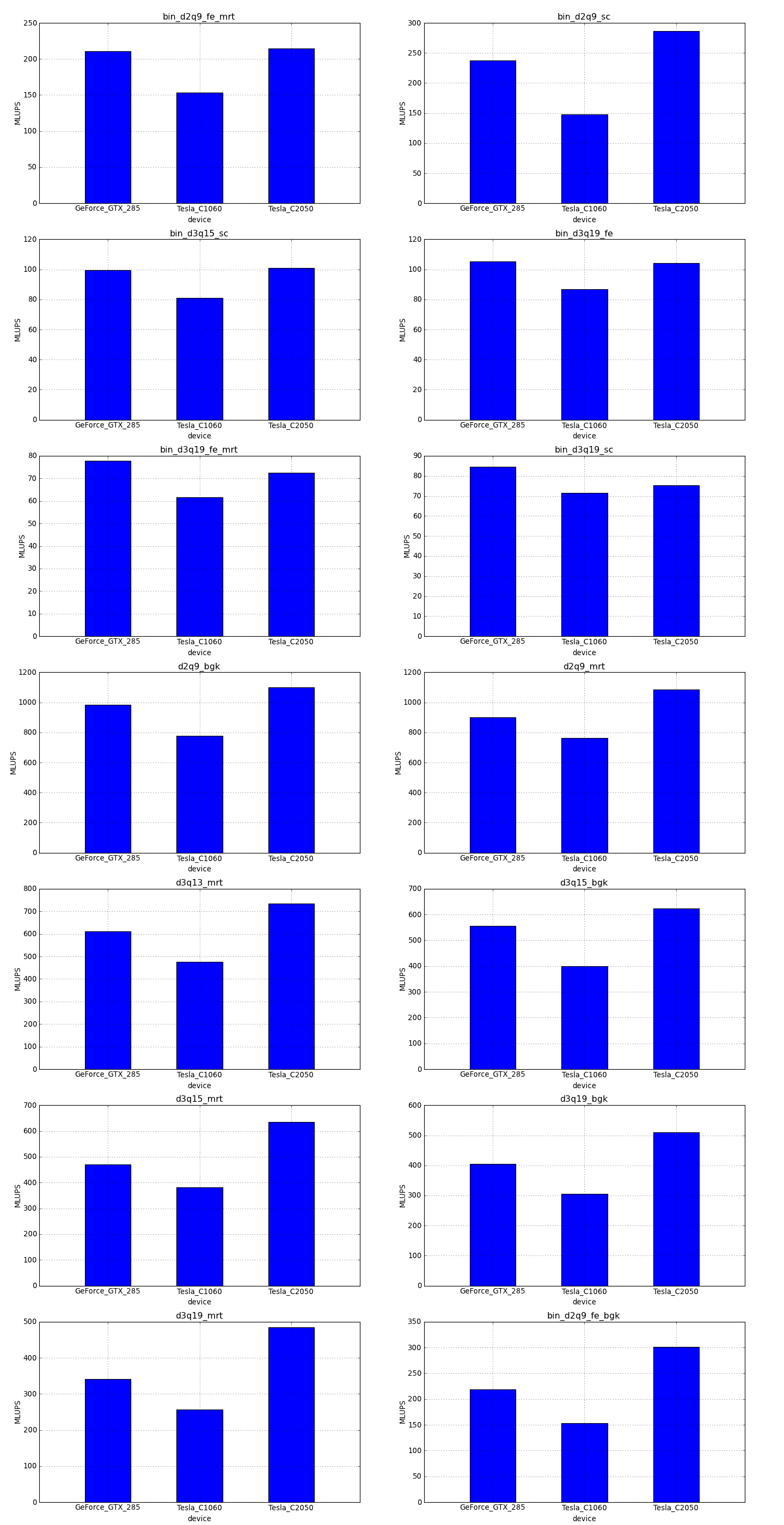
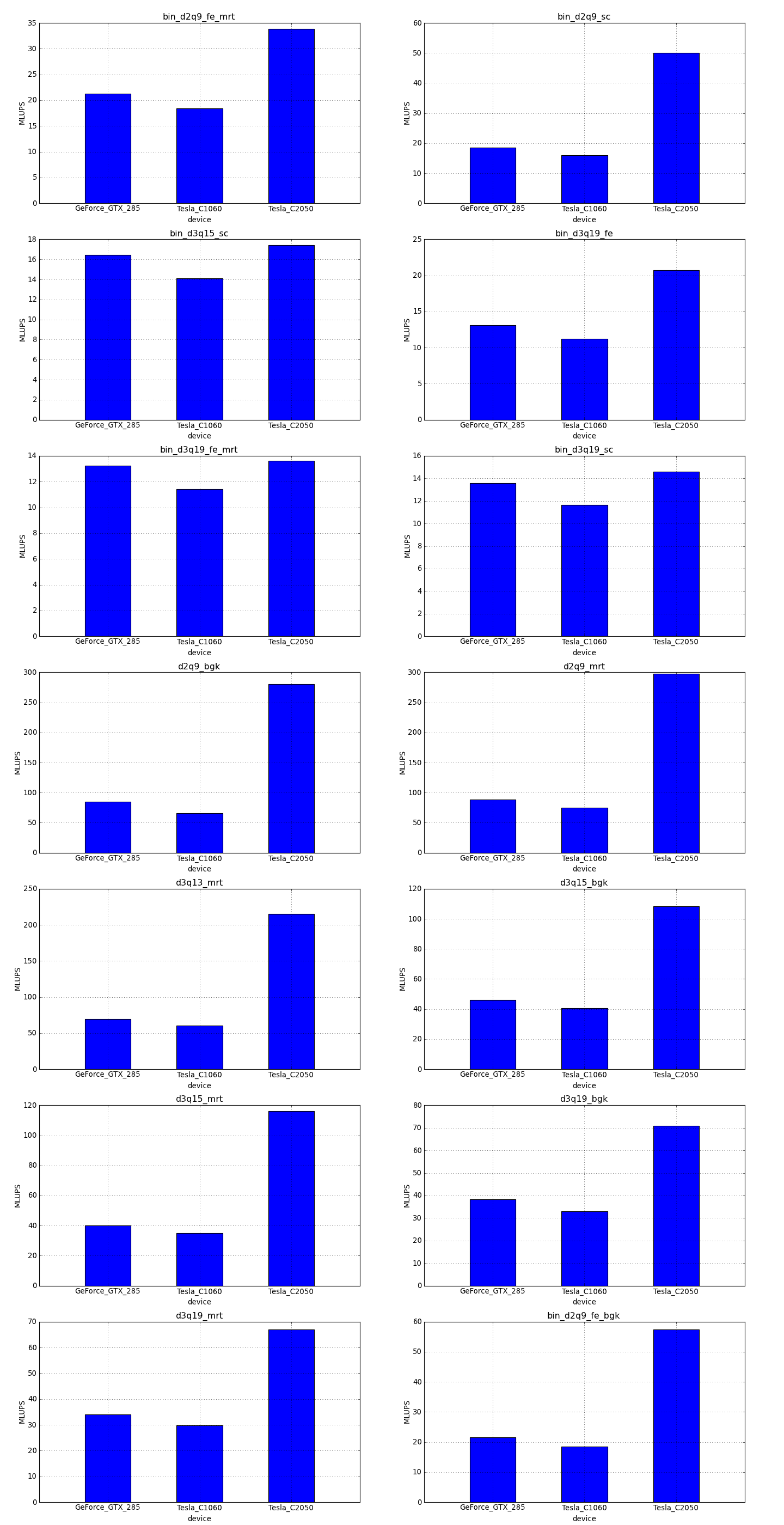
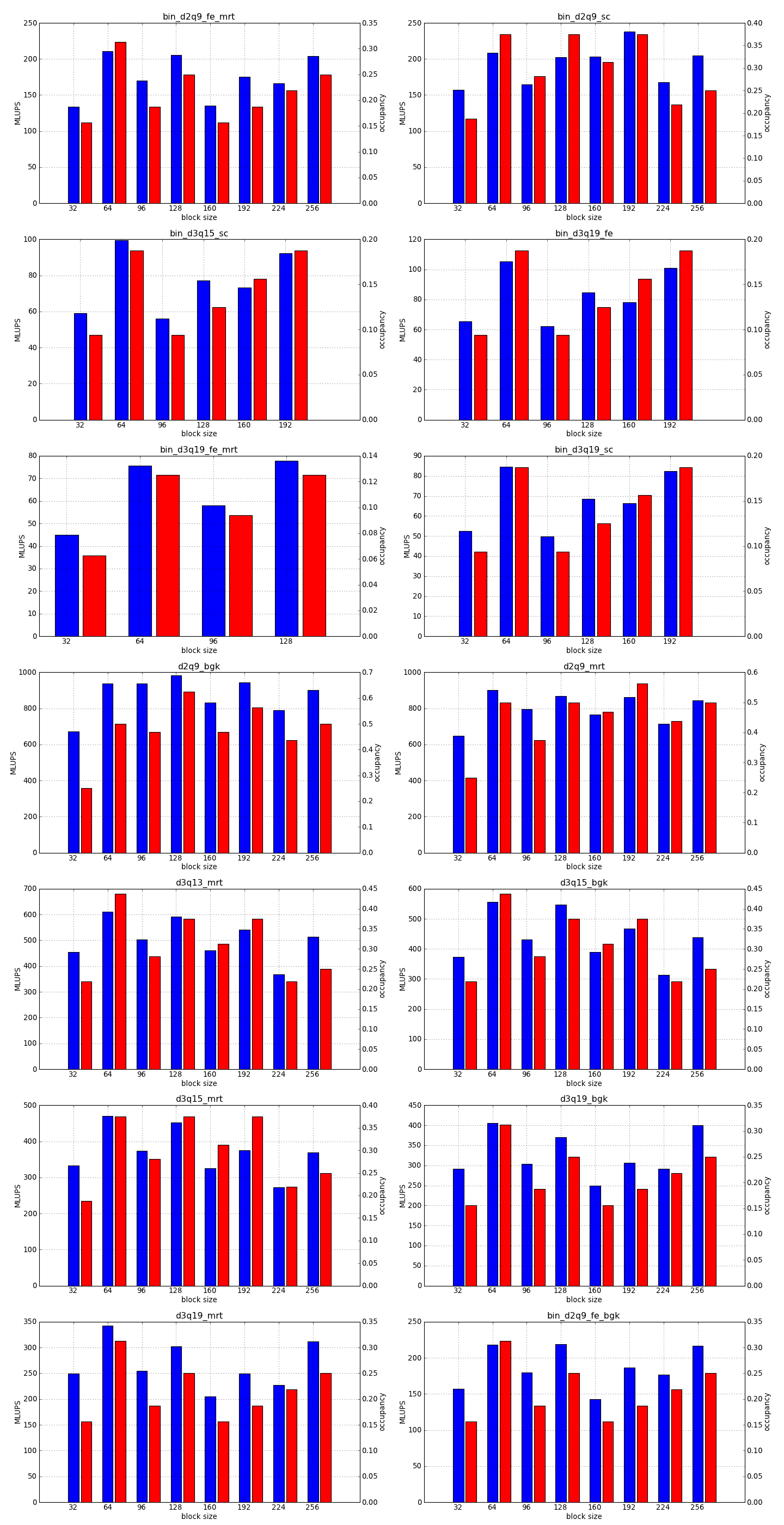
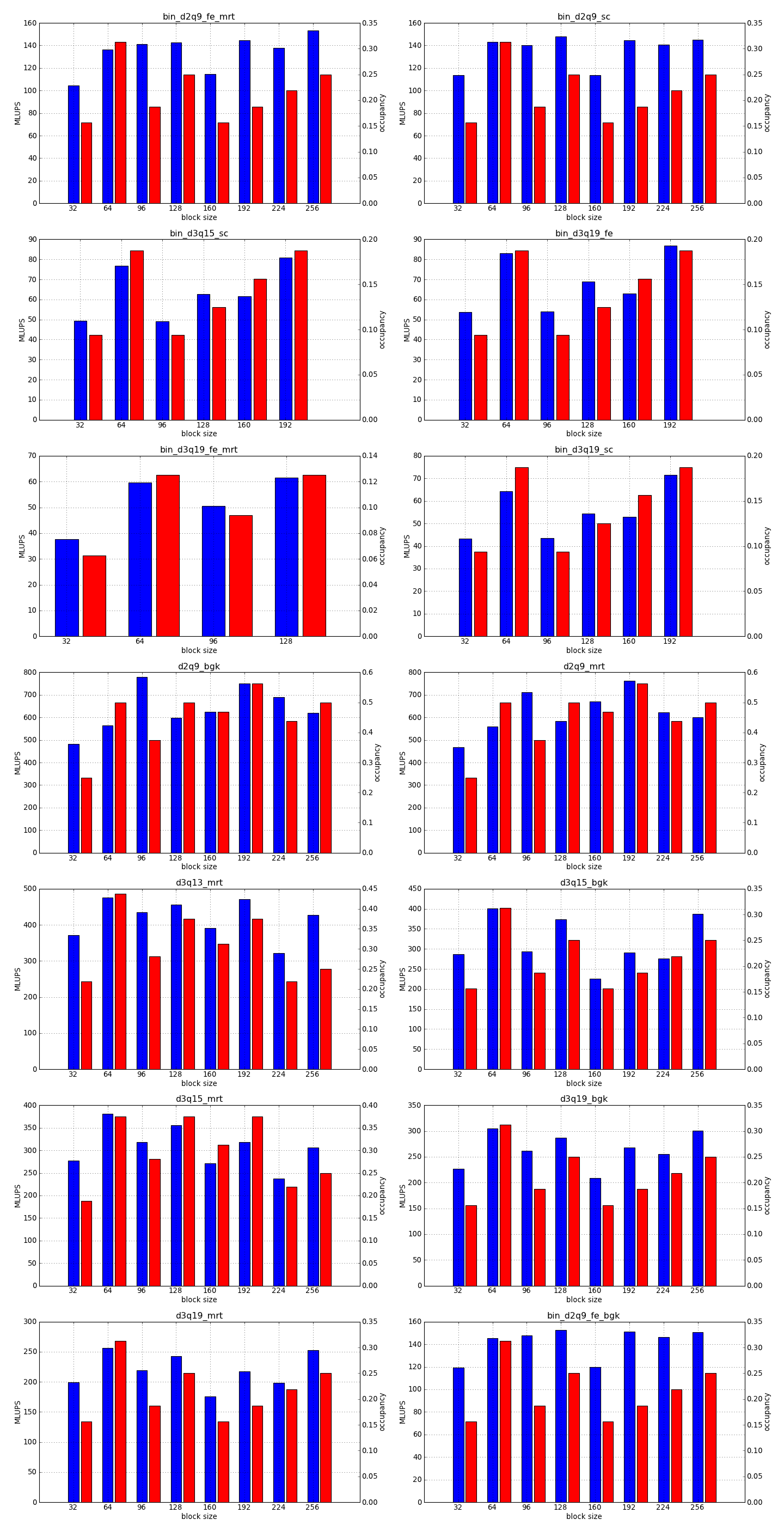
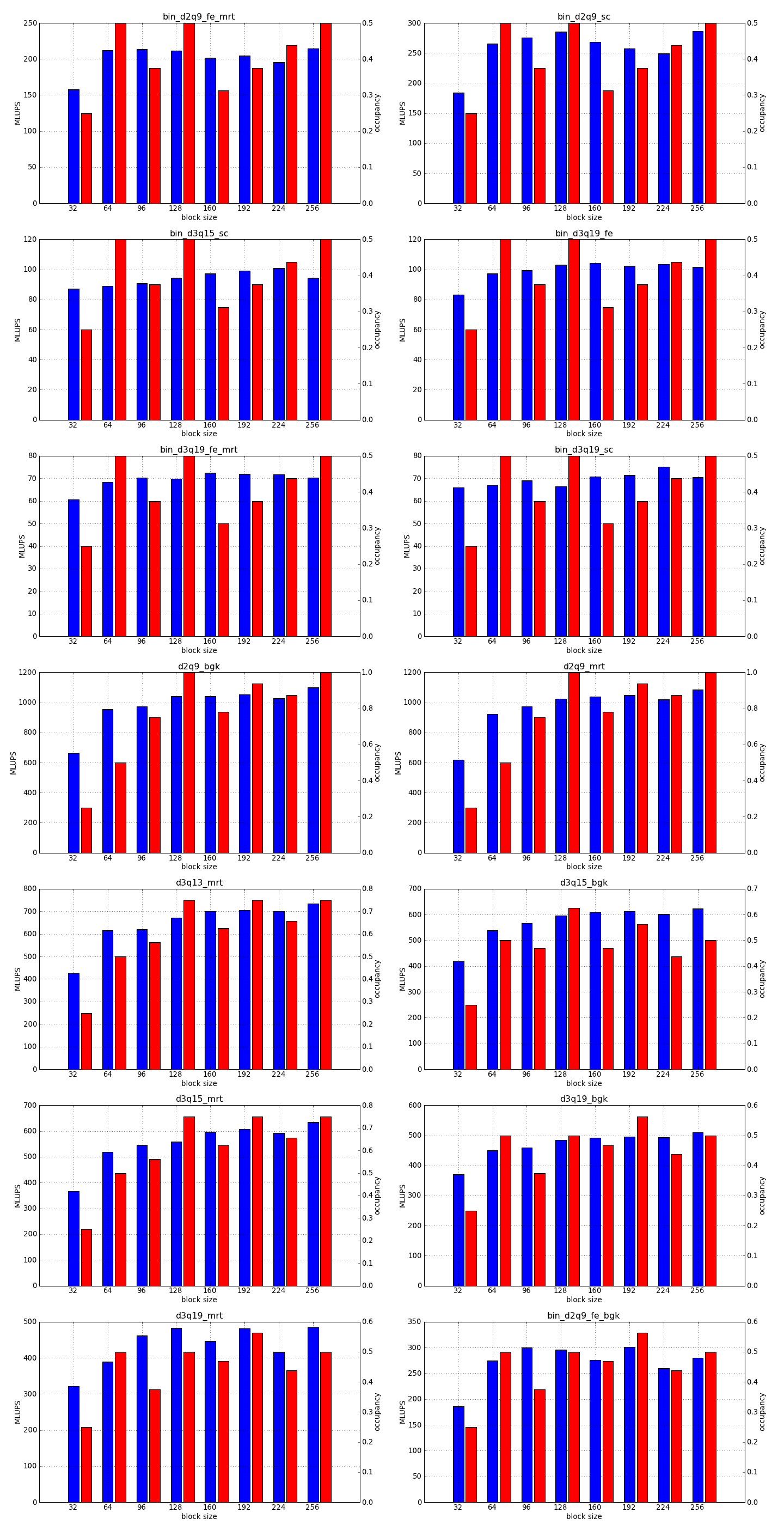
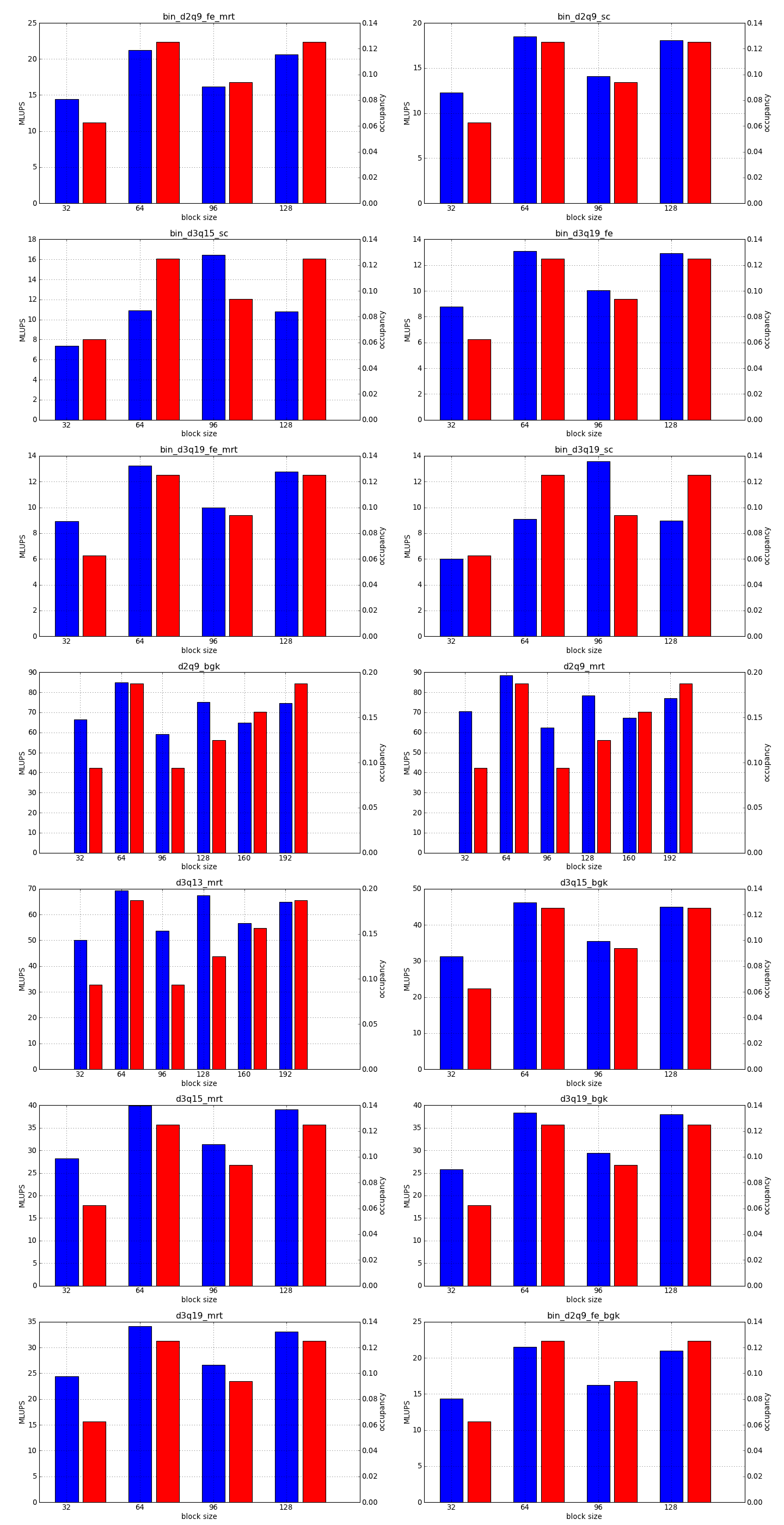
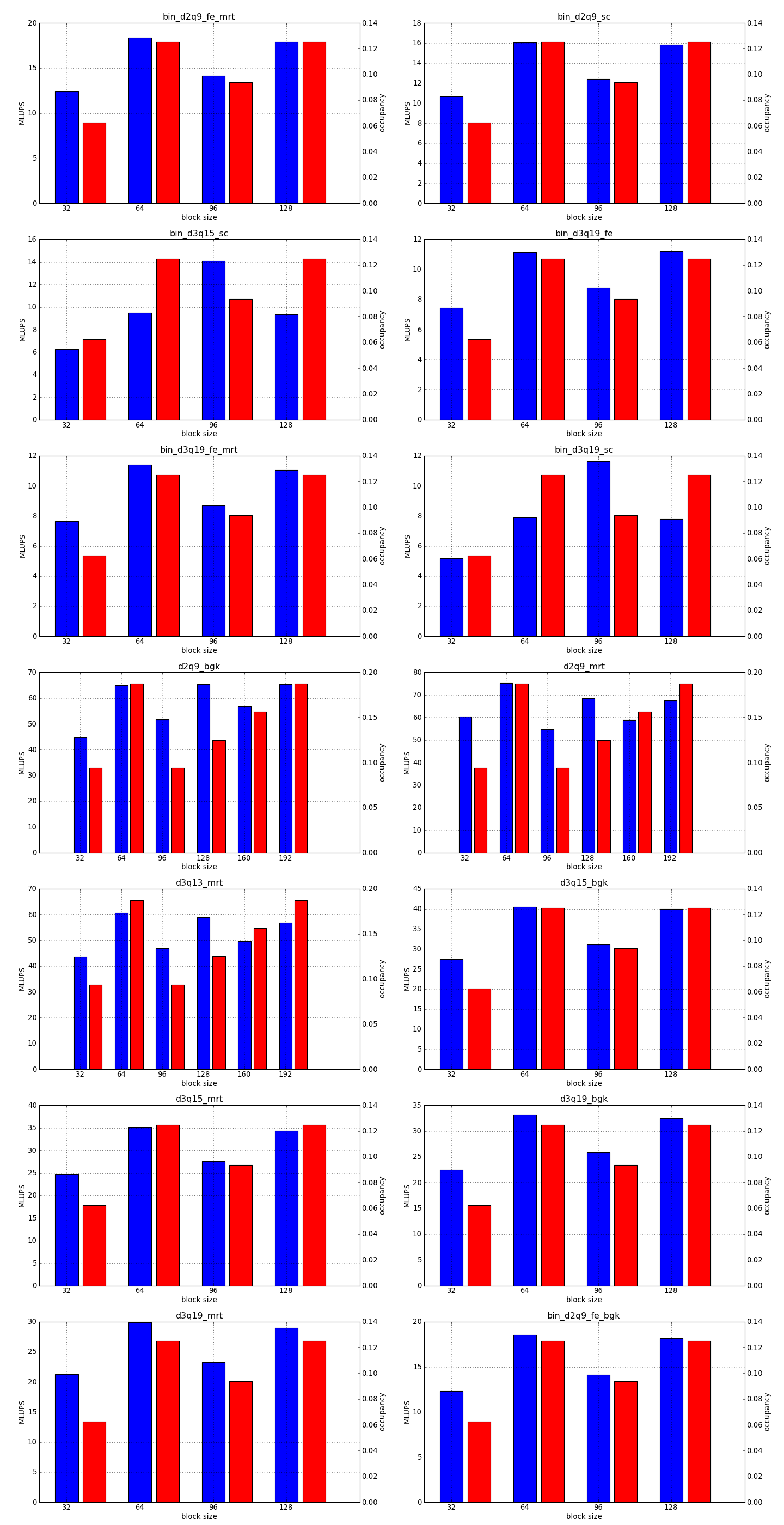
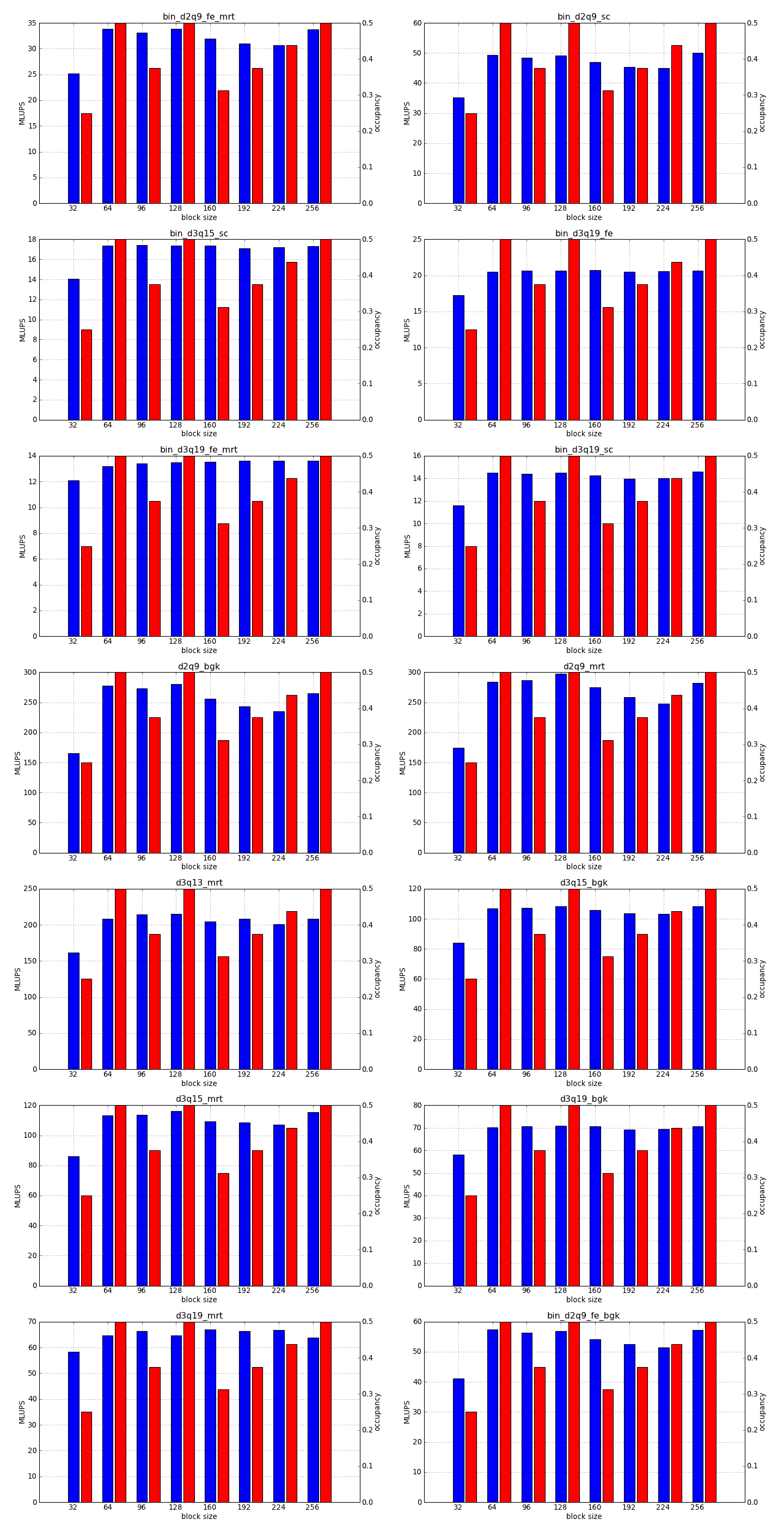
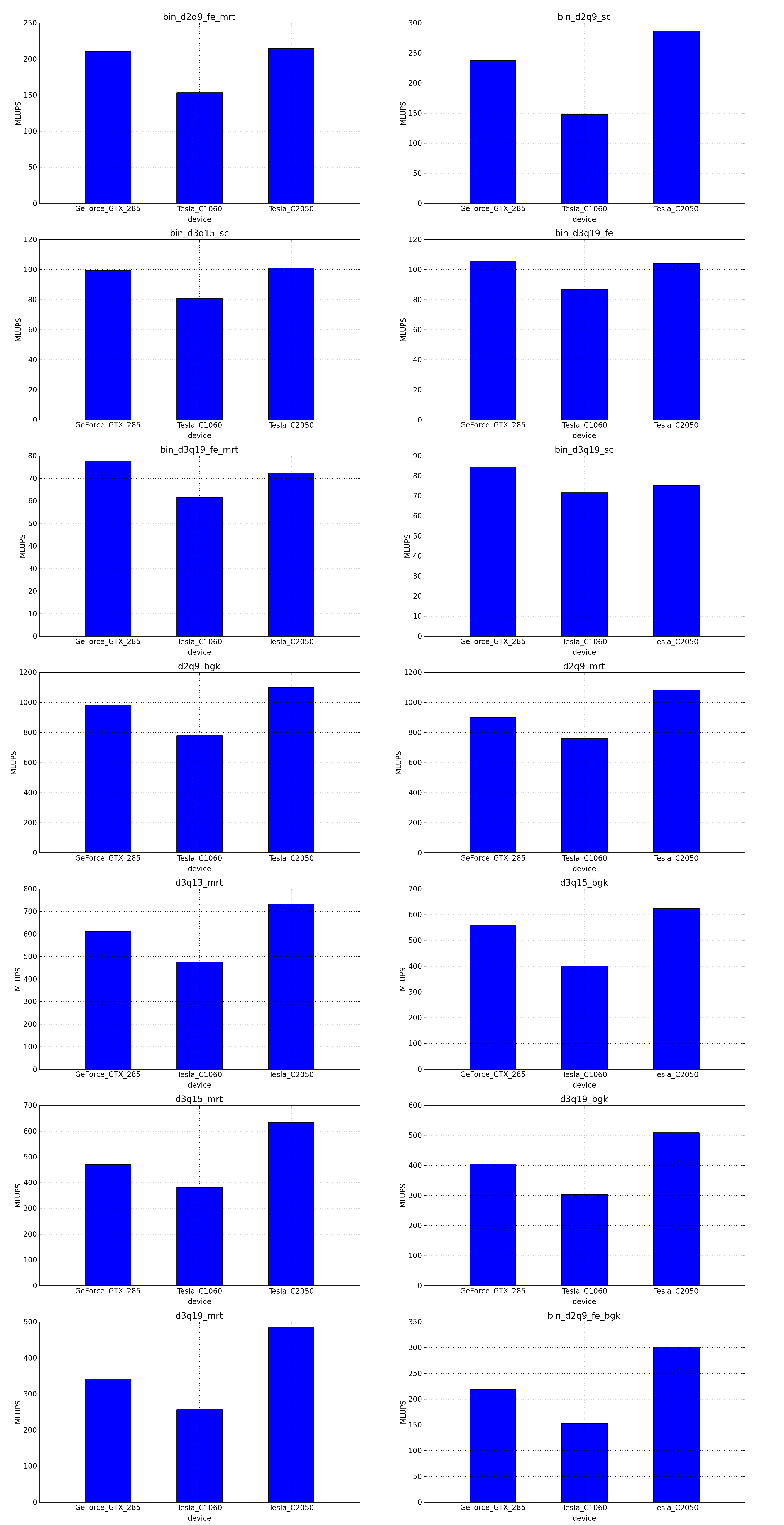
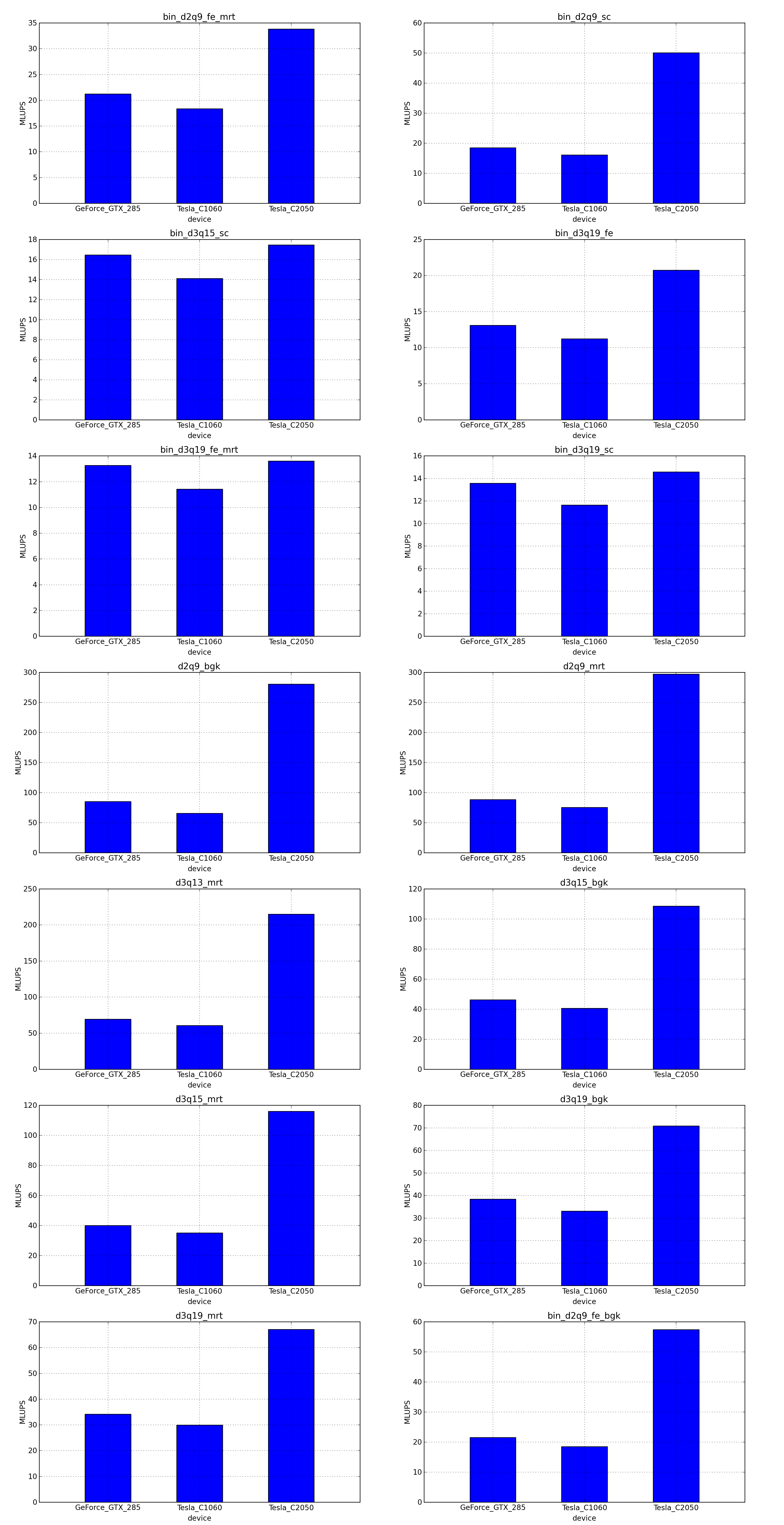
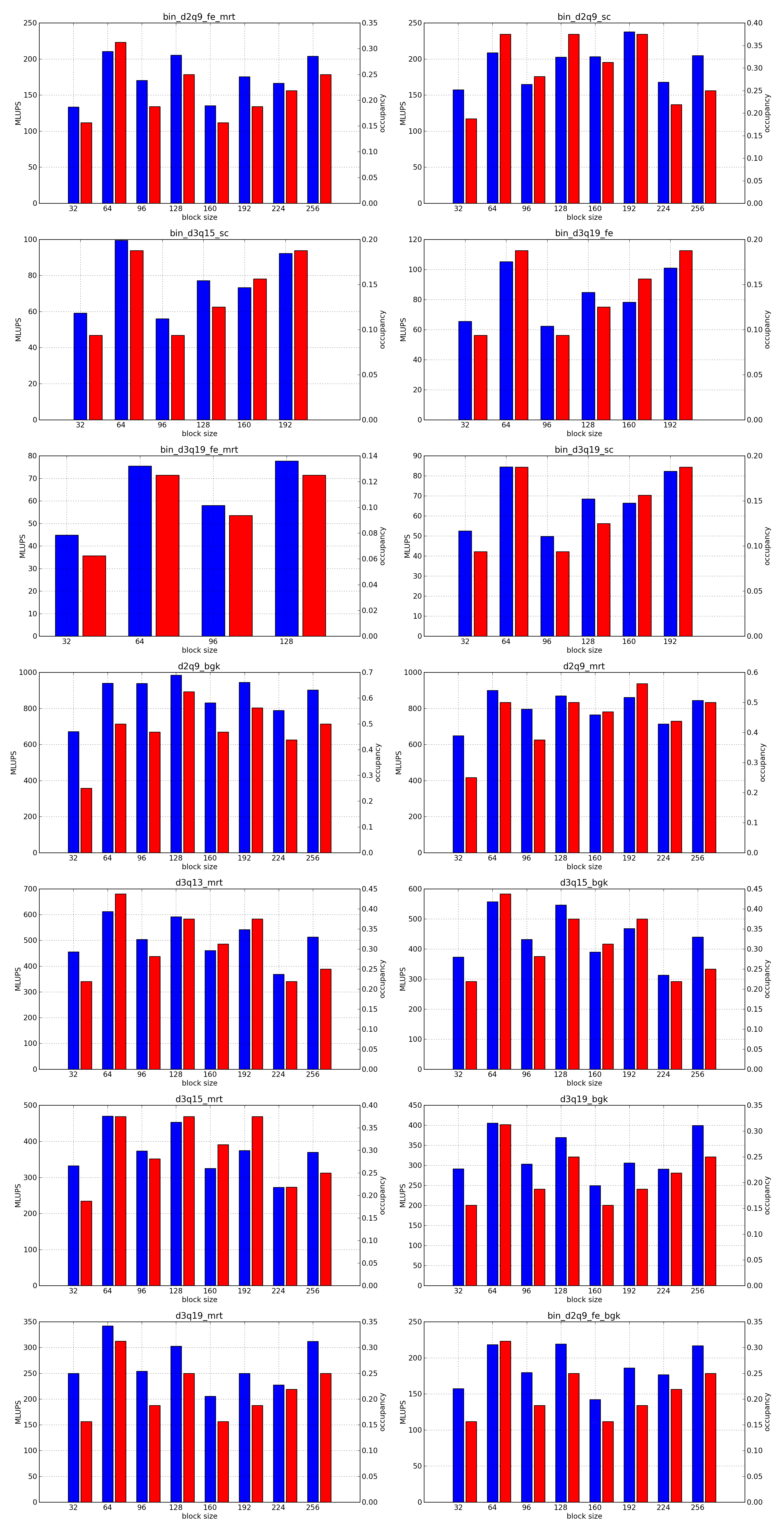
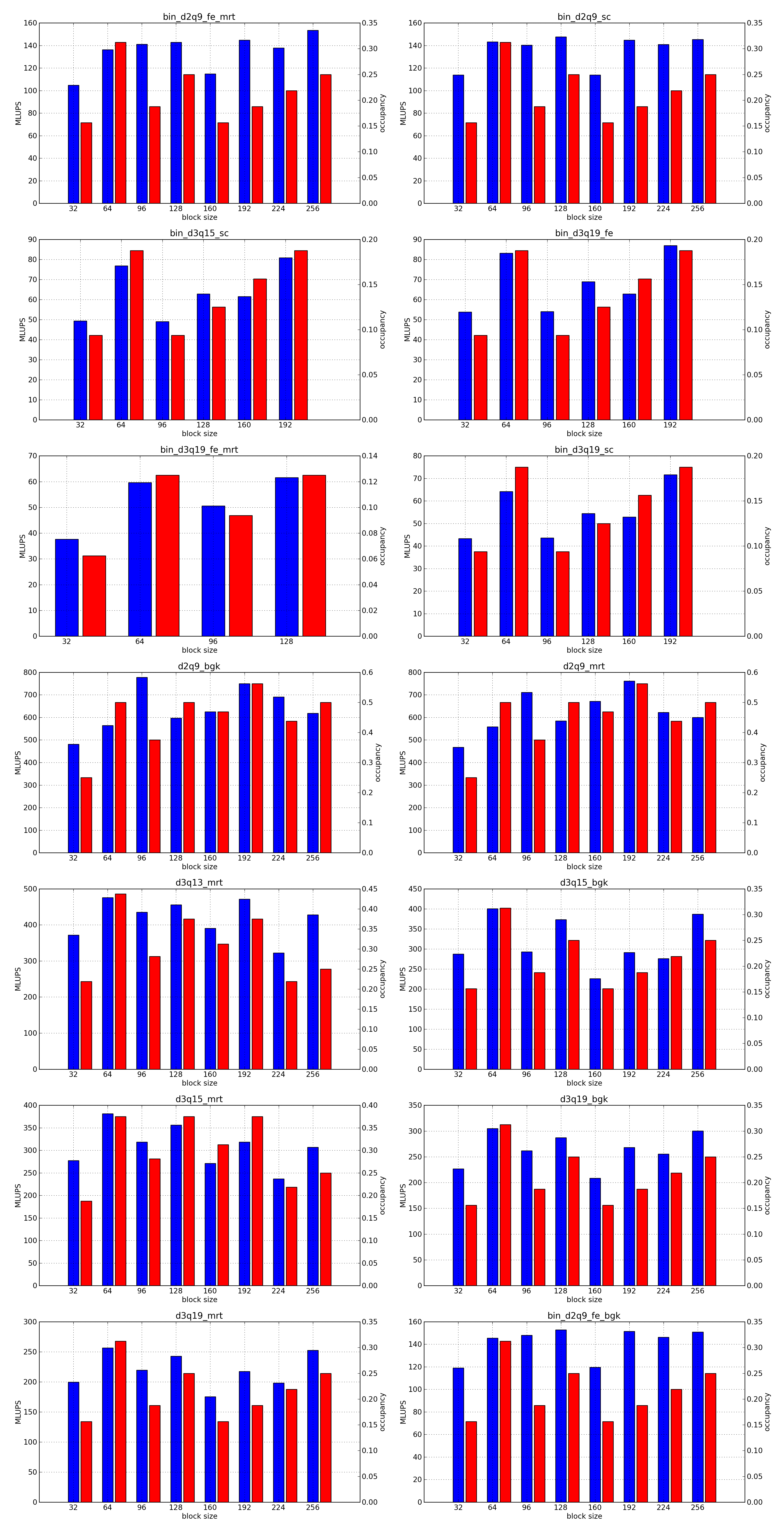
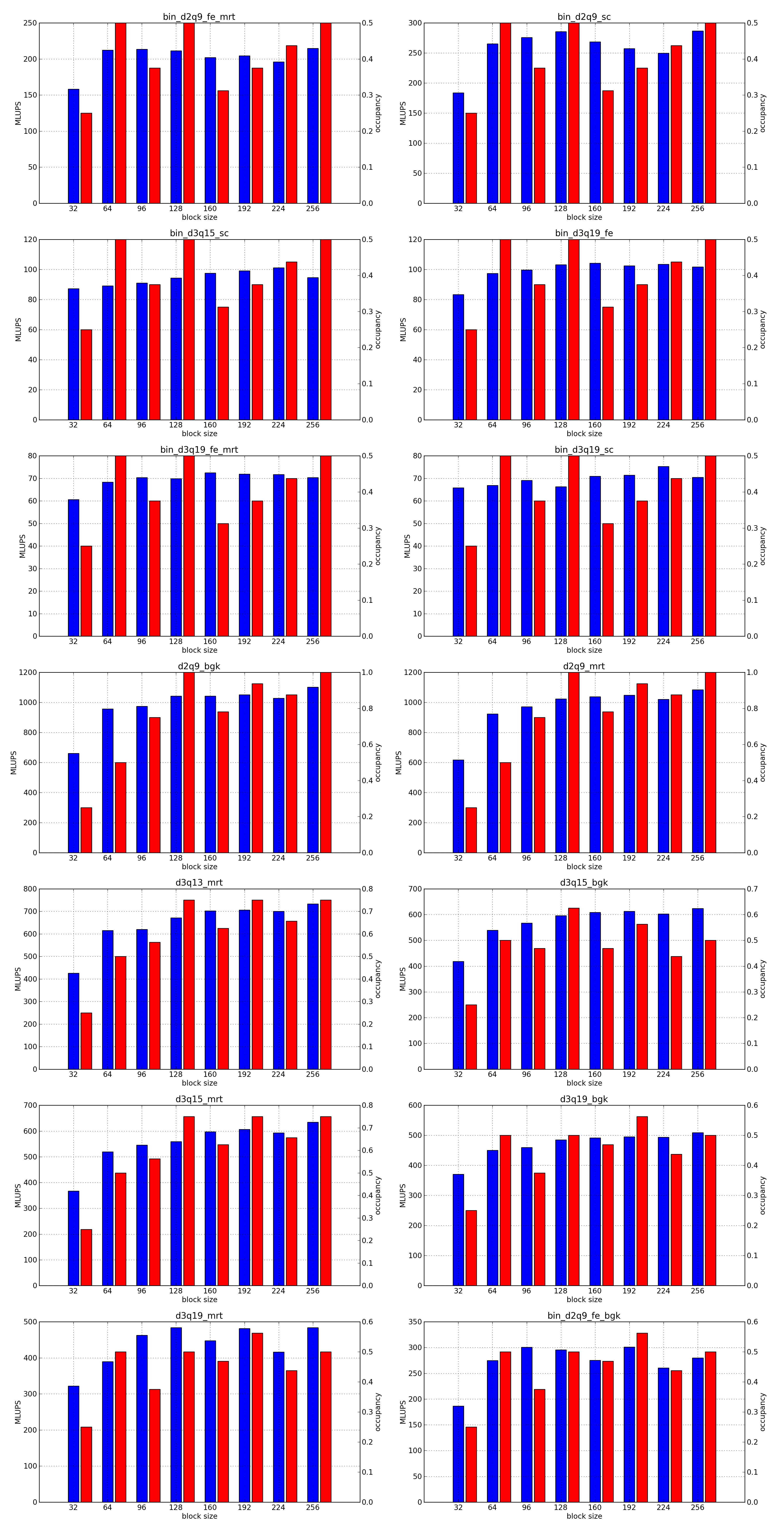
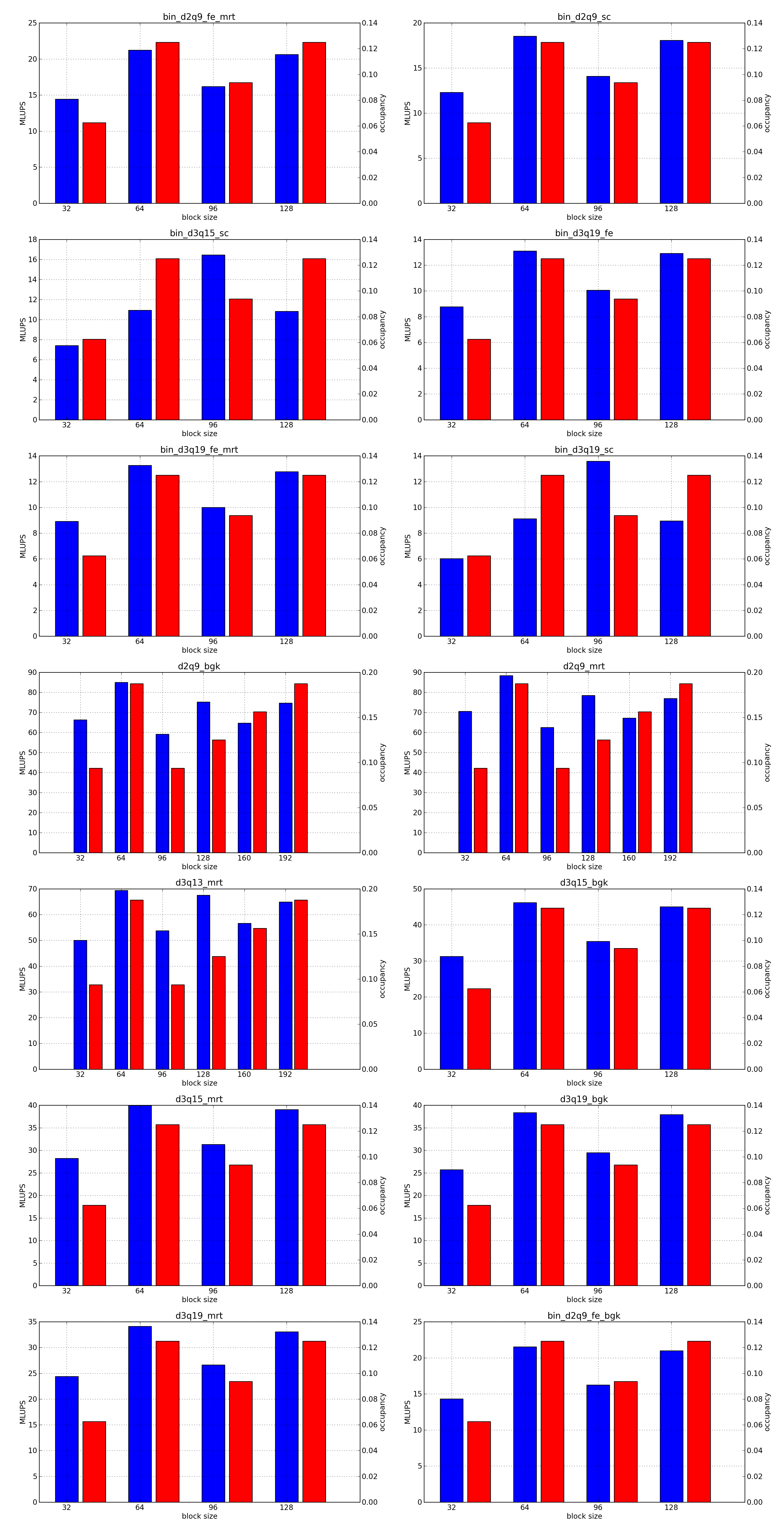
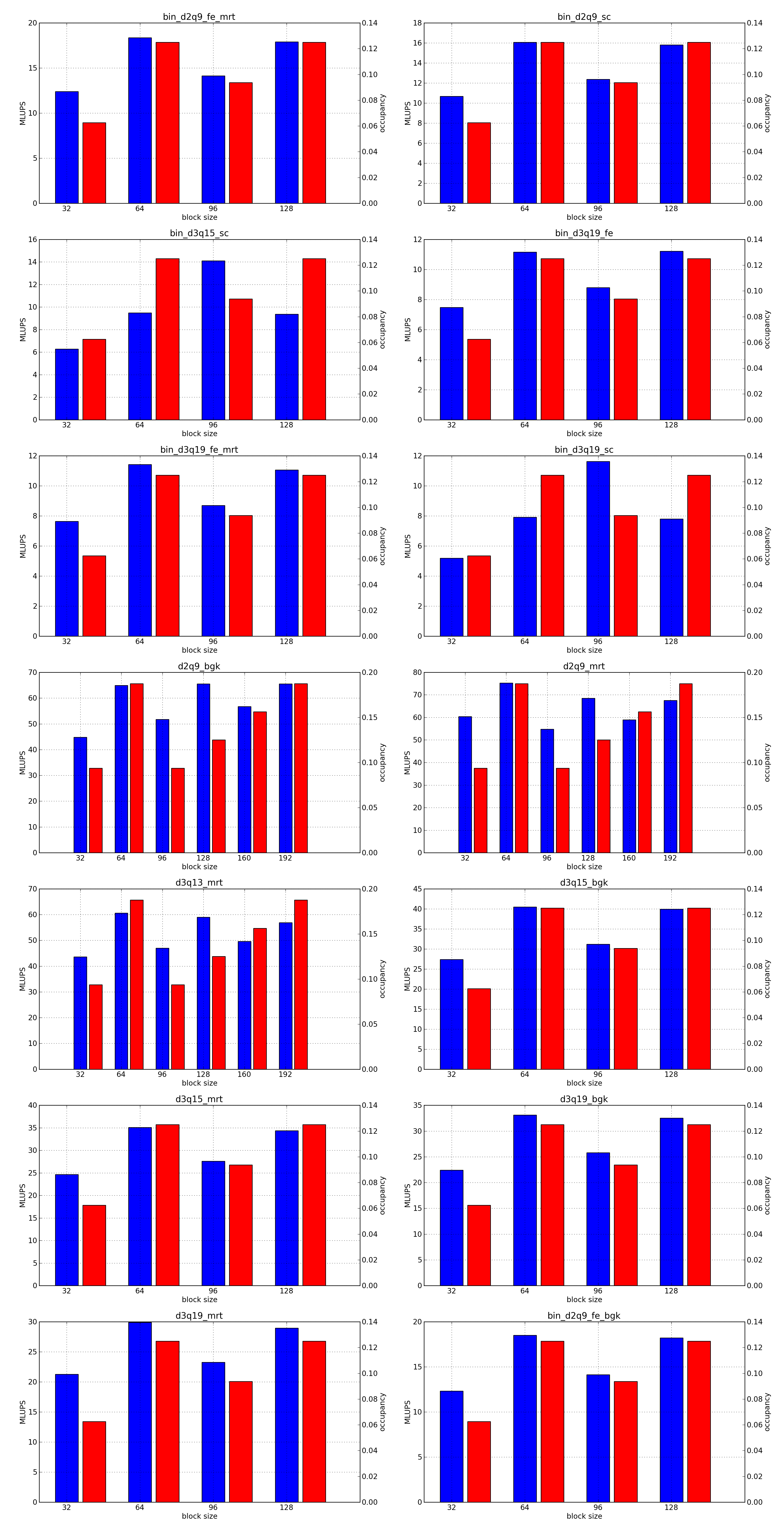
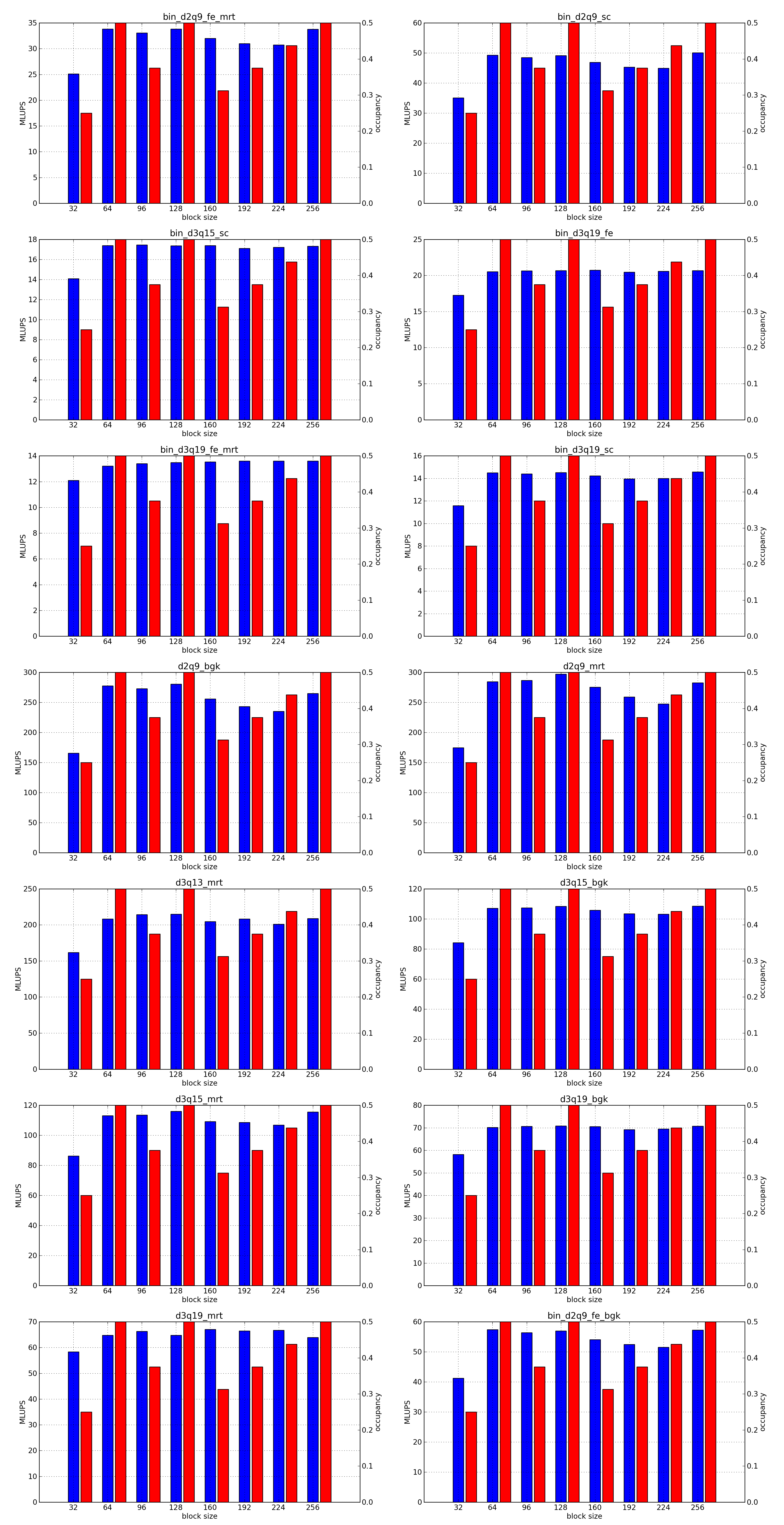
This is the simplest optimization you should apply when trying to increase the speed of a simulation. Every lattice Boltzmann node in Sailfish is processed in a separate GPU thread. These threads are grouped into 1-dimensional blocks, which allows them to exchange data. The default block size is 64. You can adjust this to a higher value using the --block_size=N command line option. Values that are multiplies of 32 should be the most effective due to the architecture of the GPU hardware.
As a rough guideline, use lower block sizes for more complex models and higher block sizes for simpler ones (e.g. 128 for single fluid, but 64 for binary fluids). The more complex the LB model used, the more registers the generated GPU code will require. You can check the number of registers used by adding --cuda-kernel-stats to your command line options. The simulation will then output something similar to:
CollideAndPropagate: l:0 s:3072 r:30 occ:(1.000000 tb:4 w:32 l:regs)
LBMUpdateTracerParticles: l:0 s:0 r:17 occ:(0.250000 tb:8 w:8 l:device)
SetInitialConditions: l:0 s:0 r:19 occ:(1.000000 tb:4 w:32 l:warps)
Each line presents, in order: name of the CUDA kernel, number of bytes of local memory, number of bytes of shared memory, number of registers, occupancy, thread blocks per multiprocessor, warps per multiprocessor, name of the factor limiting occupancy. A large number of registers will limit the occupancy, which will usually result in a lower performance of the kernel. An occupancy of 0.5 or higher is best. You only need to optimize the occupancy of the kernels that are executed the most often (e.g. CollideAndPropagate in the example above is important because it is executed for every time step. SetInitialConditions on the other hand is irrelevant, as it is only used to initialize the simulation).
Limiting register usage¶
In order to increase the occupancy, you can force the CUDA compiler to use a lower number of registers in the GPU code. This can be done via the --cuda-nvcc-opts=--maxrregcount=X which will cause the compiler to limit the number of registers to X. If you use a low value of X, some of the variables in the kernel will be moved from registers to local memory (register spilling). Local memory is much slower than the registers however, so the net effect can be a performance degradation despite the higher occupancy. Experimentation is advised.
Using fast math functions¶
CUDA code can use a faster, but less precise version of several common mathematical functions (e.g. transcendental functions such as sine, cosine, square root or the exponential function). These so-called intrinsic functions will be used if the fast math mode is turned on, which can be done using the --cuda-nvcc-opts=--use_fast_math command line option. This might slightly increase the speed of some of the more complex LB models. If you decide to apply this optimization, watch out for degraded precision (always run regression tests of our simulation) and increased register usage.
NVIDIA Fermi cards¶
Fermi devices are based on a new GPU architecture and can benefit from additional optimizations. The general guidelines presented above still apply.
By default, Sailfish uses a lower precision version of the division operator and square root function (same as in CUDA devices of compute capability 1.3 and lower). This helps with register usage and can be turned off by the --cuda-fermi-highprec option.
Block size¶
Fermi devices have more multiprocessors than GPUs of the previous generation. The multiprocessors can also handle more threads, and have better scheduling capabilities (which make it possible for the GPU to execute several different kernels simultaneously).
To fully take advantage of the available computational power, a larger block size will usually be necessary (typically twice as large as for devices of the previous generation, but make sure to check occupancy and register usage as well).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}